



TL;Ph.D.: Textual content immediate -> LLM -> Intermediate illustration (e.g. picture format) -> Secure diffusion -> Picture.
Current advances in text-to-image era utilizing diffusion fashions have achieved outstanding leads to synthesizing extremely real looking and numerous photos. Nevertheless, regardless of the spectacular capabilities of diffusion fashions resembling secure diffusion, it’s typically tough to observe cues precisely when spatial or widespread sense reasoning is required.
The determine beneath lists 4 situations the place secure diffusion can’t produce a picture that precisely corresponds to a given cue, specifically adverse, arithmeticand Attribute project, Spatial Relations. In distinction, our strategy, LLrice– Floor Ddiffusion(LMD), offering higher quick understanding of text-to-image era in these situations.

Determine 1: LLM-based Diffusion enhances the moment understanding capabilities of text-to-image diffusion fashions.
One potential resolution to this downside is in fact to gather a set multimodal dataset containing complicated subtitles and practice a big diffusion mannequin utilizing a big language encoder. This strategy is expensive: coaching giant language fashions (LLMs) and diffusion fashions is time-consuming and costly.
Our options
To unravel this downside effectively with minimal price (i.e. no coaching price), we as an alternative Equip diffusion fashions with enhanced spatial and customary sense reasoning through the use of ready-made frozen LL.M. In a novel two-stage era course of.
First, we adapt LLM right into a text-guided format generator by contextual studying. When a picture cue is offered, LLM outputs the scene format within the type of bounding packing containers and a corresponding separate description. Second, we use a novel controller-guided diffusion mannequin to supply layout-adapted photos. Each levels use frozen pre-trained fashions with none LLM or diffusion mannequin parameter optimization. We invite readers to learn the paper on arXiv for extra particulars.
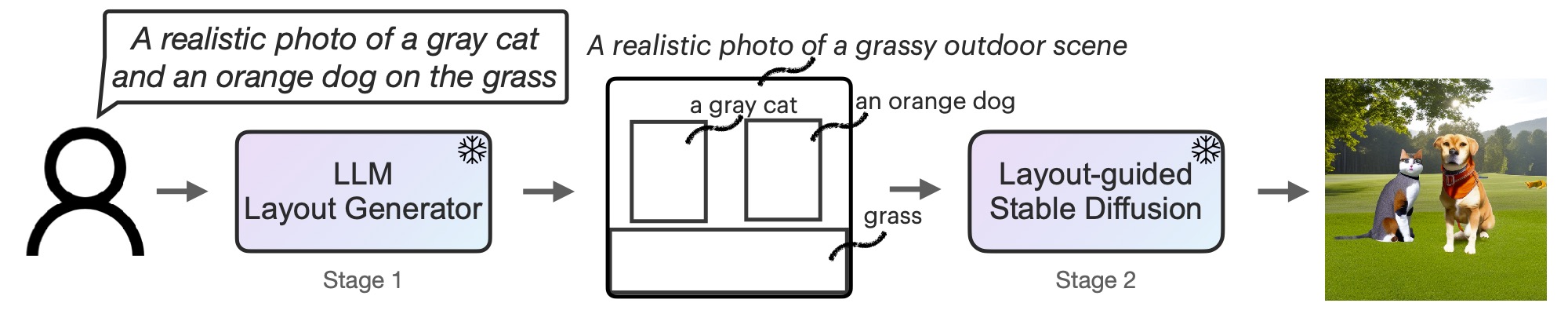
Determine 2: LMD is a text-to-image generative mannequin with a novel two-stage generative course of: text-to-layout generator with LLM + context studying and novel layout-guided secure diffusion. Each levels are training-free.
Further options of LMD
Moreover, LMD naturally permits Dialogue-based multi-turn state of affairs specification, allows further directions and subsequent modifications for every immediate.Moreover, LMD can Ideas for coping with languages whose underlying diffusion mannequin will not be nicely supported.

Determine 3: Mixed with LLM for immediate understanding, our strategy is ready to carry out conversation-based scene specification and generate prompts primarily based on languages (Chinese language within the above instance) that aren’t supported by the underlying diffusion mannequin.
Given an LLM that helps a number of rounds of dialogue (e.g., GPT-3.5 or GPT-4), the LMD permits the consumer to supply further info or directions to the LLM by querying the LLM after the primary format is generated within the dialog field, utilizing the next Command to generate picture LL.M. up to date the format in subsequent replies. For instance, the consumer can request that an object be added to the scene or that the placement or description of an current object be modified (left half of Determine 3).
Moreover, by giving an instance of a non-English immediate with English format and background description throughout contextual studying, LMD accepts the enter of the non-English immediate and generates a format with English field descriptions and background for for subsequent use. Format to picture era. As proven in the precise half of Determine 3, this enables prompts to be generated in languages that aren’t supported by the underlying diffusion mannequin.
visualize
We confirm the prevalence of our design by evaluating it with the essential diffusion mannequin (SD 2.1) used within the backside layer of LMD. We invite readers to make further evaluations and comparisons of our work.
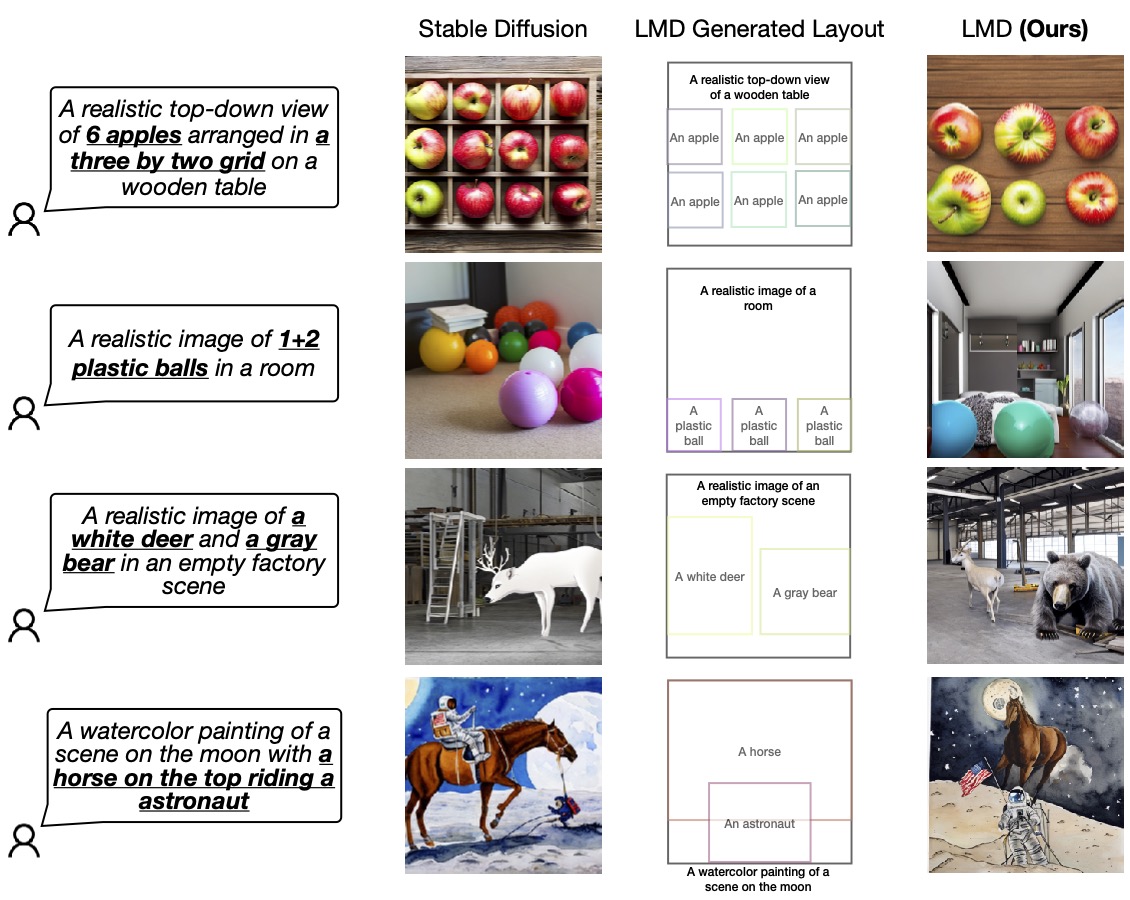
Determine 4: LMD outperforms primary diffusion fashions in precisely producing photos primarily based on cues requiring verbal and spatial reasoning. LMD may generate counterfactual text-to-images that the essential diffusion mannequin can’t (final row).
For extra particulars on LLM Fundamental Diffusion (LMD), please go to our web site and browse the paper on arXiv.
bibliographic textual content
If diffusion primarily based on the LLM has impressed your work, please cite it as follows:
@article{lian2023llmgrounded,
title={LLM-grounded Diffusion: Enhancing Immediate Understanding of Textual content-to-Picture Diffusion Fashions with Giant Language Fashions},
creator={Lian, Lengthy and Li, Boyi and Yala, Adam and Darrell, Trevor},
journal={arXiv preprint arXiv:2305.13655},
12 months={2023}
}