



Structured Question Language (SQL) is a posh language that requires information of databases and metadata. At present, generative synthetic intelligence may help these with out SQL information. This generative AI activity is named text-to-SQL, which makes use of pure language processing (NLP) to generate SQL queries and convert textual content into semantically appropriate SQL. The answer on this article is designed to take enterprise analytics operations to the subsequent degree through the use of pure language to shorten information paths.
NLP-based SQL technology has undergone a significant shift with the arrival of enormous language fashions (LLMs). The LL.M. has demonstrated superior efficiency and is now capable of generate correct SQL queries from pure language descriptions. Nonetheless, challenges stay. First, human language is inherently obscure and context-dependent, whereas SQL is exact, mathematical, and structured. This hole might outcome within the consumer’s necessities not being precisely translated into the generated SQL. Second, you might have to create text-to-SQL performance for every database, since information is usually not saved in a single goal. You will have to re-establish performance for every database to allow customers to generate NLP-based SQL. Third, regardless of the widespread adoption of centralized analytics options similar to information lakes and warehouses, the complexity will increase as a result of the desk names and different metadata required to construct SQL for the required information sources are totally different. Subsequently, amassing complete, high-quality metadata stays a problem. To study extra about text-to-SQL greatest practices and design patterns, see Producing worth from enterprise information: Greatest practices for Text2SQL and generative AI.
Our answer is designed to handle these challenges utilizing Amazon Bedrock and AWS Analytics Providers. We use Anthropic Claude v2.1 on Amazon Bedrock for our LLM. To handle these challenges, our answer first merges metadata from information sources into the AWS Glue information catalog to enhance the accuracy of the SQL queries generated. This workflow additionally features a ultimate analysis and remediation loop in case Amazon Athena (used downstream because the SQL engine) discovers any SQL points. Athena additionally permits us to overwrite numerous information sources utilizing numerous supported endpoints and connectors.
After finishing the steps to construct the answer, we’ll present the outcomes of some take a look at eventualities with totally different ranges of SQL complexity. Lastly, we talk about the right way to merely mix totally different information sources right into a SQL question.
Resolution overview
Our structure consists of three key parts: Retrieval Augmentation Technology (RAG) with database metadata, a multi-step self-correction loop, and Athena because the SQL engine.
We use the RAG technique to retrieve the desk description and schema description (columns) from the AWS Glue metastore to make sure that the request is expounded to the proper desk and information set. In our answer, we arrange the steps to run the RAG framework utilizing the AWS Glue catalog for demonstration functions. Nonetheless, you may also use the information base in Amazon Bedrock to rapidly construct a RAG answer.
The multi-step part permits the LL.M. to appropriate the accuracy of the generated SQL queries. Right here, the generated SQL is distributed to test for syntax errors. We use Athena error messages to counterpoint LLM’s prompts in order that extra correct and environment friendly corrections may be made within the generated SQL.
You may think about Athena’s occasional error messages as suggestions. The price affect of the error correction step is negligible in comparison with the worth delivered. You may even use these corrective steps as a supervised reinforcement studying paradigm to fine-tune your LL.M. Nonetheless, for the sake of simplicity, we don’t cowl this course of within the publish.
Please observe that generative AI options naturally include inherent dangers of inaccuracy. Although Athena error messages are very efficient at mitigating this threat, you may add extra controls and views, similar to handbook suggestions or pattern queries for fine-tuning, to additional decrease this threat.
Athena not solely permits us to repair the SQL question, however it additionally simplifies the general drawback for us as a result of it acts because the hub and the spokes are the a number of sources of information. Entry administration, SQL syntax, and so forth. are all dealt with via Athena.
The diagram under exhibits the structure of the answer.
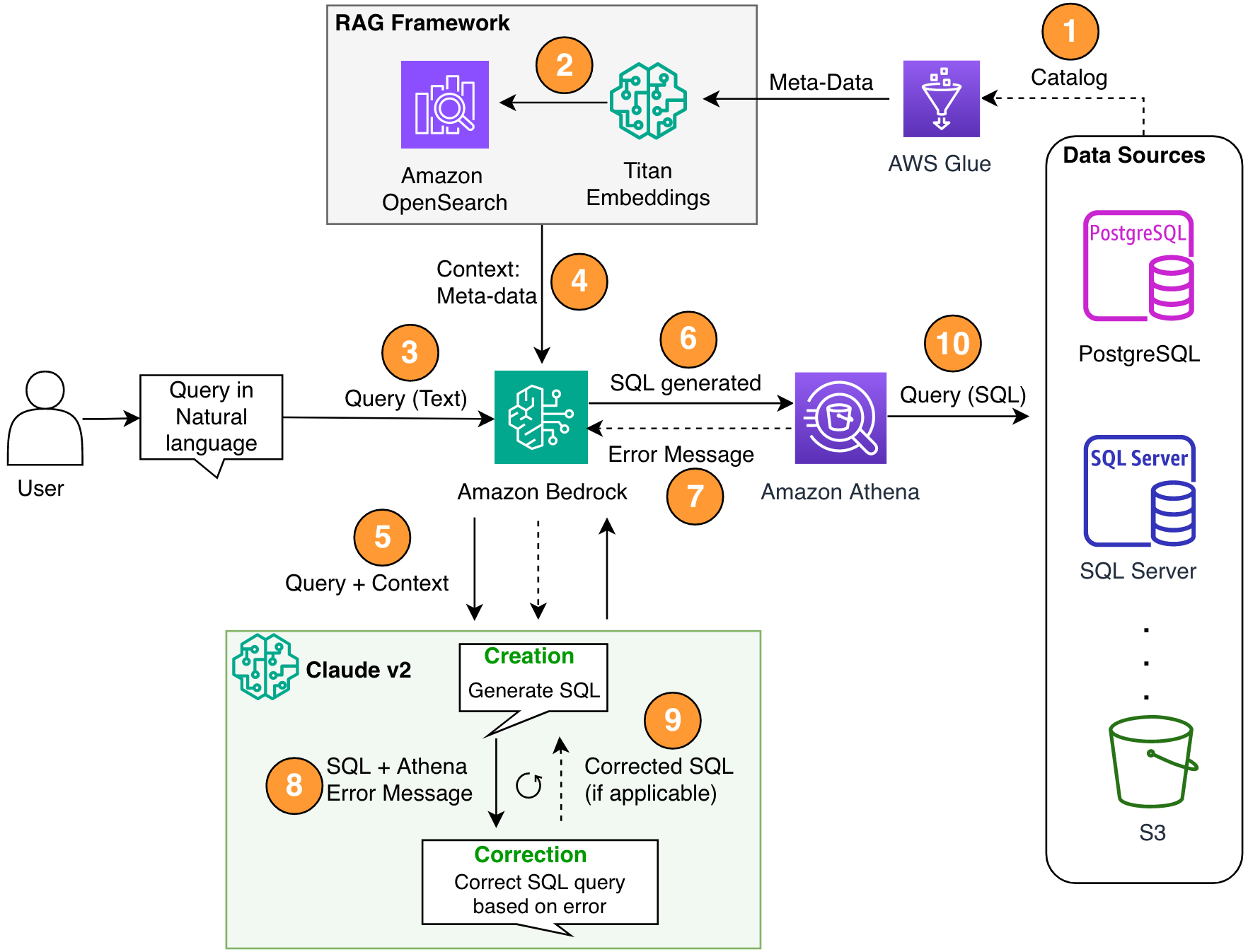
Determine 1. Resolution structure and course of.
This course of contains the next steps:
- Use the AWS Glue crawler (or different technique) to create an AWS Glue information listing.
- Utilizing the Titan-Textual content-Embeddings mannequin on Amazon Bedrock, metadata is transformed into embeddings and saved in an Amazon OpenSearch Serverless vector retailer, which acts as a information base within the RAG framework.
At this stage, the method is able to obtain pure language queries. Steps 7-9 symbolize the calibration cycle (if relevant).
- Customers enter queries in pure language. You should utilize any net software to offer a chat UI. Subsequently, we didn’t cowl UI particulars within the publish.
- The answer applies the RAG framework via similarity search, which provides extra context from the metadata of the vector database. This desk is used to seek out the proper tables, databases and properties.
- The question is merged with the context and despatched to Anthropic Claude v2.1 on Amazon Bedrock.
- This mannequin takes the generated SQL question and connects to Athena to validate the syntax.
- If Athena offers an error message stating that the syntax is inaccurate, the mannequin will use the inaccurate textual content from Athena’s response.
- New immediate added Athena’s response.
- The mannequin builds the corrected SQL and continues the method. This iteration may be carried out a number of instances.
- Lastly, we use Athena to run the SQL and produce output. Right here, the output is offered to the consumer. For the sake of architectural simplicity, we don’t present this step.
conditions
For this text, it is best to meet the next conditions:
- Have an AWS account.
- Set up the AWS Command Line Interface (AWS CLI).
- Arrange the SDK for Python (Boto3).
- Use the AWS Glue crawler (or different technique) to create an AWS Glue information listing.
- Utilizing the Titan-Textual content-Embeddings mannequin on Amazon Bedrock, metadata is transformed into embeddings and saved in an OpenSearch Serverless vector retailer.
Implement the answer
You should utilize the next Jupyter pocket book, which accommodates all of the code snippets offered on this part, to construct your answer. We advocate utilizing Amazon SageMaker Studio to open this pocket book, which accommodates the ml.t3.medium occasion with the Python 3 (information science) core. For directions, see Prepare a machine studying mannequin. Please full the next steps to arrange your answer:
- Create a information base for the RAG framework within the OpenSearch service:
- Development Ideas (
final_question) by combining pure language consumer enter (user_query), associated metadata from vector storage (vector_search_match), and our directions (particulars): - Calls Amazon Bedrock for LLM (Claude v2) and prompts it to generate a SQL question. Within the code under, it makes a number of makes an attempt as an example the self-correction steps: x
- If there are any issues with the generated SQL question (
{sqlgenerated}) Response from Athena ({syntaxcheckmsg}), new immediate (immediate) is generated based mostly on the response, and the mannequin tries once more to generate new SQL: - After the SQL is generated, name the Athena consumer to execute and generate output:
Check answer
On this part, we execute our answer utilizing totally different pattern eventualities to check SQL queries of various complexity.
To check our text-to-SQL, we used two information units offered by IMDB. A subset of IMDb materials is offered for private and non-commercial use. You may obtain the dataset and retailer it in Amazon Easy Storage Service (Amazon S3). You should utilize the next Spark SQL code snippet to create a desk in AWS Glue.For this instance we use title_ratings and title:
Retailer information in Amazon S3 and metadata in AWS Glue
On this case, our dataset is saved in an S3 bucket. Athena has an S3 connector that lets you use Amazon S3 as a queryable supply.
For our first question, we offer the enter “I am new to this. Are you able to assist me view all tables and columns within the imdb schema?”
Right here is the ensuing question:
The next screenshot and code present our output.

For the second question, we ask for “Present all titles and particulars within the US with a ranking higher than 9.5.”
Listed below are the queries we generated:
Reply is as follows.

For the third question, we typed “Nice Response! Now present me all authentic style video games with a ranking above 7.5 that aren’t in america.”
The next question was produced:
We get the next outcomes.

Generate self-correcting SQL
This state of affairs simulates a SQL question with syntax points. Right here, the generated SQL will self-correct based mostly on Athena’s response.In her subsequent response, Athena gave COLUMN_NOT_FOUND error and talked about table_description Unable to resolve:
Mix options with different sources
To make use of this answer with different sources, Athena handles the be just right for you. To do that, Athena makes use of supply connectors that can be utilized with federated queries. You may consider connectors as extensions to the Athena question engine. Pre-built Athena supply connectors can be found for sources similar to Amazon CloudWatch Logs, Amazon DynamoDB, Amazon DocumentDB (suitable with MongoDB), and Amazon Relational Database Service (Amazon RDS), in addition to JDBC-compliant relational sources similar to MySQL and PostgreSQL) Apache 2.0 license. After organising a connection to any information supply, you should utilize the earlier code library to increase the answer. For extra info, see Question any supply utilizing Amazon Athena’s new federated queries.
clear up
To wash up assets, you may first clear up the S3 bucket the place the info is situated. There are not any prices except your app calls Amazon Bedrock. Within the curiosity of infrastructure administration greatest practices, we advocate deleting the assets established on this demonstration.
in conclusion
On this article, we suggest an answer that lets you use NLP to generate complicated SQL queries via varied assets supported by Athena. We additionally enhance the accuracy of generated SQL queries via a multi-step analysis loop based mostly on error messages from downstream processes. Moreover, we use metadata from the AWS Glue information catalog to think about desk names queried via RAG framework queries. We then examined the answer in varied real-world eventualities with totally different ranges of question complexity. Lastly, we mentioned how the answer may be utilized to the totally different information sources supported by Athena.
Amazon Bedrock is on the coronary heart of this answer. Amazon Bedrock may help you construct many generative AI purposes. To get began with Amazon Bedrock, we advocate you observe the quickstarts within the following GitHub repository and turn into accustomed to constructing generative AI purposes. It’s also possible to strive the information base in Amazon Bedrock to rapidly construct such a RAG answer.
Concerning the writer
 Sanjib Panda is a knowledge and machine studying engineer at Amazon. With a background in AI/ML, Information Science and Large Information, Sanjeeb designs and develops progressive information and ML options that clear up complicated technical challenges and obtain strategic targets for world 3P sellers managing their companies on Amazon. Along with his work as a knowledge and machine studying engineer at Amazon, Sanjeeb Panda is an avid foodie and music lover.
Sanjib Panda is a knowledge and machine studying engineer at Amazon. With a background in AI/ML, Information Science and Large Information, Sanjeeb designs and develops progressive information and ML options that clear up complicated technical challenges and obtain strategic targets for world 3P sellers managing their companies on Amazon. Along with his work as a knowledge and machine studying engineer at Amazon, Sanjeeb Panda is an avid foodie and music lover.
 Bulak Gezluklu is a Principal AI/ML Skilled Options Architect situated in Boston, MA. He helps strategic clients undertake AWS applied sciences, particularly generative AI options, to realize their enterprise targets. Burak holds a PhD in aerospace engineering from METU, a grasp’s diploma in techniques engineering, and a postdoc in system dynamics from the Massachusetts Institute of Know-how in Cambridge, Massachusetts. Brack stays a analysis affiliate with MIT. Brack is captivated with yoga and meditation.
Bulak Gezluklu is a Principal AI/ML Skilled Options Architect situated in Boston, MA. He helps strategic clients undertake AWS applied sciences, particularly generative AI options, to realize their enterprise targets. Burak holds a PhD in aerospace engineering from METU, a grasp’s diploma in techniques engineering, and a postdoc in system dynamics from the Massachusetts Institute of Know-how in Cambridge, Massachusetts. Brack stays a analysis affiliate with MIT. Brack is captivated with yoga and meditation.